

What you’ll find in this article:
- From multirepos structure to monorepo
- Enhancing the development process with custom-made scripts
- Main changes in the deployment process
- Wrapping up: Monorepo, yes or no?
Imagine a project run on Ruby on Rails used by several clients and/or services, where each one employs a different version of the project. One team can be working on a new feature for a specific client, and everything is functioning fine on their end, but when they merge this feature on the main gem, it breaks for other clients, and everything is a mess.
Unfortunately, you won’t need an overactive imagination to envision such a scenario since it’s common in projects that grow in size and infrastructure. However common this might be, most teams get used to living with the problem. So, progressively, the workflow becomes tortuous, maintenance more expensive, and Continuous Integration straightly chimerical. The team has to spend valuable time running tests and modifying the main gem. Consequently, releasing turns into a painful experience that consists of bumping a gem on the repos used and ensuring all the versions are correct.
We recently faced this problem firsthand while working for an e-Commerce SaaS that powers many e-Commerce sites, whose architecture and workflow had become hard to manage. This is how we handled its migration to monorepos and the improvements in CI/CD we implemented to work efficiently for the whole team.
Monorepos, in a nutshell
While reviewing the SaaS we considered various options but with one clear goal: to develop a Ruby on Rails solution that was customizable for each client but that still shared functionalities via libraries. We found the answer in the monorepo approach was the answer to our problem, both from a technical and workflow point of view.
Simply put, it consists of merging all the projects and their dependencies (gems) into one repository. This means that each project’s versions of gems will stop being used, and they will all use the current version.
From multirepos structure to monorepo
To understand the impact of this switch, let’s look first at how things were functioning before. As you can see in the comparison below, the multirepos structure was quite monolithic. Thus, to make the new architecture work, we introduced some rework on CI, CD, Folder Organization and the GIT process.
CI - Codeship:
- Multirepo: One codeship pipeline per repo
- Monorepo: Custom scripts that only run specs for touched projects
CD - Heroku builds via Codeship:
- Multirepo: Automatic deploys tied to each pipeline
- Monorepo: Automatically deploys on a specific server based on the changes or branch
Folder organization:
- Multirepo:
- One repo per folder
- Shared libraries maintained and versioned on Gemfury for privacy
- Monorepo:
- Bin:
- The scripts that ease the repo management CI/CD, setup etc…
- Implementations
- Where we have each project customization for each client.
- All implementations: name like client-implementation
- Shared:
- This folder contains a gems folder that is placed in the root of the project at the moment of deploy (using a buildpack)
- New gems/shared libs should be added here
- Bin:
GIT:
- Multirepo: Master -> Staging -> Production
- Monorepo: Master -> Staging and Production branch per project
Improving the repository design was a significant first step, for sure. However, to enhance both developers' and teams' collaboration, we needed to add some modifications to the development and deployment process, which really made this approach shine.
Unfortunately, the tooling options for monorepo on Rails aren’t so many, and we couldn’t recur to an out-of-the-box solution. For instance, popular tools like Bazel or Yarn are tough to set up, but most importantly, they aren’t Ruby-specific. Had we used them, we would have still had to adapt them for this end. Therefore, we decided to build our scripts; some based on existing solutions; and others (like the CI/CD ones we’ll see below), were coded from scratch.
Enhancing the development process with custom-made scripts
We needed to make the developers’ work seamless so we focused on creating a series of scripts, that run the following functions:
- Running any rails-related command: migration, generate model, etc.
- Running tests/linter.
- Running a specific application.
- De-duplicate migrations across projects.
- Make a deployment running specifically for an application.
Main changes in the deployment process
For the new deployment process of the SaaS app we worked on following a 2-level testing approach before production, each with its own environment: in this case, Staging and QA.
In the new design, everything branches from the Master branch the same as it was. The difference is that each implementation now has its staging and release branches that allow us to control what gets released onto each implementation. To achieve this we’ve built custom scripts that detect change on a folder, run specs for that folder/project and automate its deployment.
How does the CI/CD process work in QA?
The CI automatically detects the implementation with changes or changes in the shared gem and then runs the spec for all the changed ones upon deploy. We do something similar on CD’s side: changes are detected, and then only the implementations with changes are built. However, this works differently for QA and Stage/Prod, as you can see in the following diagram:
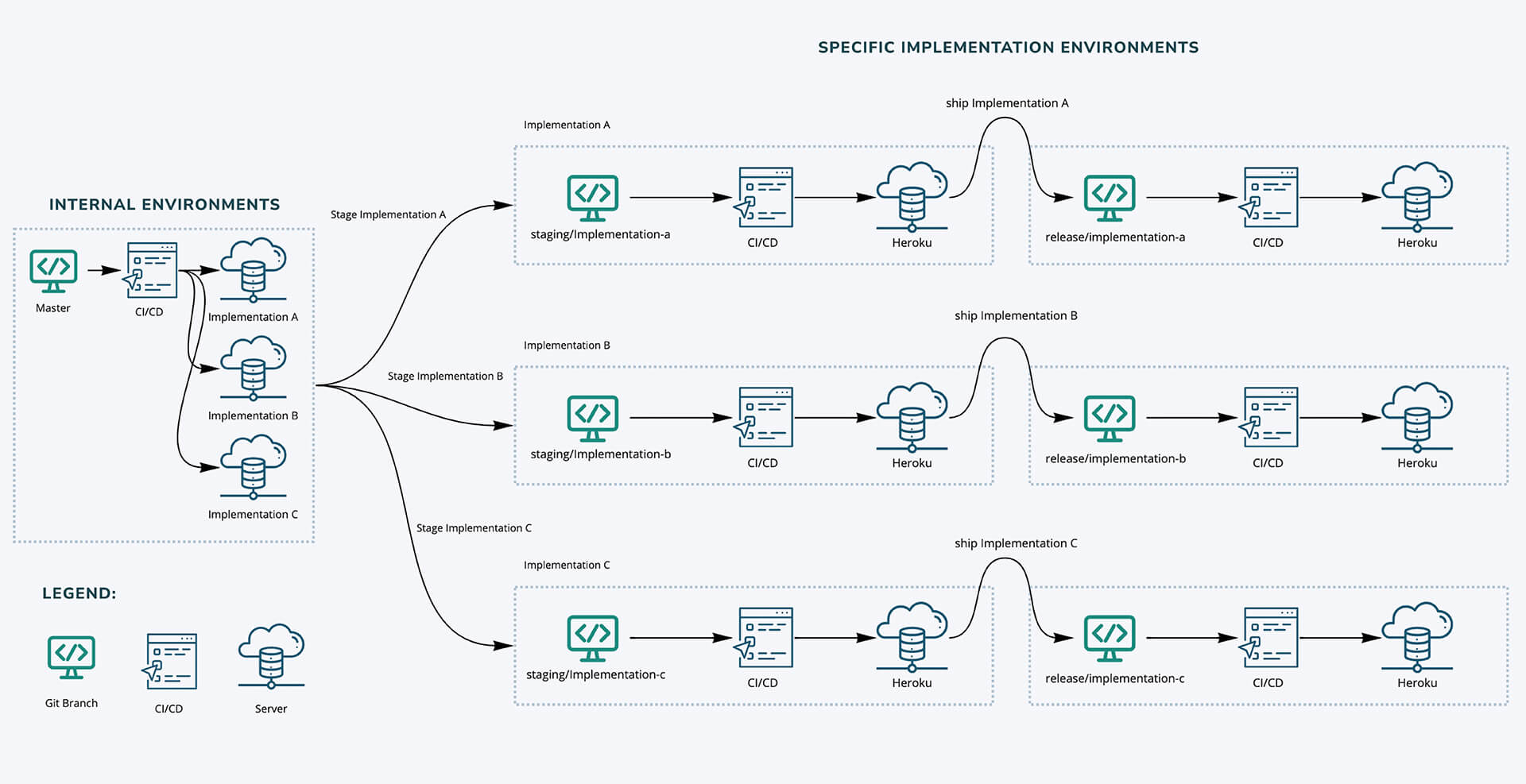
CI/CD scripts in action
In our CI process, we automatically detect which implementation has changed using a git command and some ruby help:
def ci_changed_projects
return @ci_changed_projects if defined?(@ci_changed_projects)
@ci_changed_projects = {}
changes_cmd = `git log -m -n 1 --name-only --pretty=format:"" | sort | uniq -u`
if changes_cmd.size.zero?
print_log 'no changes'
return @ci_changed_projects
end
changes_cmd.split.each do |change|
dir_struct = change.split('/')
next unless %w[implementations shared].include? dir_struct[0]
is_a_gem = dir_struct[0] == 'shared'
next if is_a_gem && !dir_struct.include?('god-gem')
project = dir_struct[is_a_gem ? 2 : 1]
@ci_changed_projects[project] = is_a_gem unless @ci_changed_projects.key?(project)
end
@ci_changed_projects
end
To deploy to a specific server in CD, we use the following script plus a custom build pack, which specifically picks the project for that Heroku instance and re-arranges the gemfile and package.json to be in the root directory. This way, we keep the slug size small and dependencies well managed.
The CI/CD process in Staging
On Staging it’s a different story because we wanted to be able to manage releases on the client level since there are different tiers/hotfixes. Thus, we maintained a specific branch per client.
The three main differences here are that we don’t need to have a pipeline for each Repo, that we can have scripts to run specs for all projects once a shared library is updated, and that there is no need to update the projects to have specific gem version (i.e.: pointing to a gem branch) in case there are changes.
Wrapping up: Monorepo, yes or no?
This kind of implementation is never good or bad per se, but it depends on the size and complexity of the project, the current workflow of your team, and the bandwidth you might have for the migration process. We leave you here the bright and the dark side of the monorepo for you to consider, and three critical pieces of advice to bear in mind when migrating a Ruby on Rails project as this one from multirepos to a monorepo.
The benefits of the Monorepo approach
After implementing this solution the benefits have been evident in our project’s workflow. These are the key benefits we have found:
- Better developer onboarding
- Everything becomes easier as the developers get everything they need to make changes on any project with a simple clone command.
- Faster and smoother development
- Easier to run customizations locally for shared libraries as they’re not versioned.
- Each implementation has a cleaner migration, gems and js dependency files. For our approach, in particular, each new implementation is mostly a fork of the standard one, while having a monorepo where we were able to build scripts that avoid duplication of these across projects
- Easier deploys
- We no longer need to bump gem versions before each deploy.
- Code reviews become more simple
- Despite having bigger PR’s which isn’t actually a good thing, we now can see how a change affects multiple projects/libs in 1 Pull Request
The disadvantages of Monorepos
As usual, it’s not all a bed of roses and there are downsides to this approach:
- Bigger size, greater maintenance
- The first one is that the repo starts growing in size rapidly and that the codebase to support the monorepo needs periodic maintenance.
- Broken master, blocked teams
- Any broken changes on master will affect everyone working in the monorepo, so you need to be extra careful there.
- Migration can be hard
- The migration process is not easy and it can take considerable time to be implemented properly and train existing team members on the new approach.
3 things to keep in mind when migrating to a Monorepo
So, if after weighing benefits and disadvantages you want to go ahead with the Monorepo approach, here are 3 pieces of advice for the transitioning period. Applying these will make all the difference.
- Projects can’t be updated right away
- To solve this one we’ve kept some gems pointing to the versioned version of the gem and not the one in the monorepo so we could update it later.
- Projects will temporarily use different versions because of different features/tiers.
- Here we’ve developed a branching mechanism where branches would contain specific versions of a project for releases. Thanks to this, we could solve the issue of each project having different versions at a different point in time.
- Only pick the specific project and dependencies upon deployment
- This was achieved by customizing an existing monorepo heroku buildpack. We picked the implementation based on an env variable and moved its dependencies to the root folder of the project. Also we had to change gemfile.lock and package.json to point to the correct place.


