

What is deep learning?
Machine learning is currently used for a wide range of applications, such as scanning for tumours in medical patients or identifying probabilities in circumstances such as financial trading or weather prediction. It’s also used in everyday consumer applications, for example a shopping app that continually improves its product recommendations for you based on what you purchase or view.
More broadly, it can be used wherever a piece of software would benefit from learning from examples and in cases where it would essentially be impossible for developers to anticipate and code for every example, current and new. Driverless cars use deep learning to help them to understand what to do when they see a particular road sign, or how to react in a hundreds of different, very specific circumstances (although it is well publicised that there have been some big teething problems).
Tiago also points out that deep learning is used to improve translations and to transcribe audio, for software to learn the differences (or similarities) between animal species or other real world elements, and for improving voice or face recognition.
Implementing deep learning
 When we, as humans, first encounter something that we’ve never seen before, we try and work out what it is
based on several factors. We use our own inbuilt neural network to find points of reference, memories and
perhaps colours and shapes that we can refer to. So, if you see an unusual animal for the first time, for
example a Capybara, you might say, “It’s got
four legs and brown fur… Is it a cat?” But you can see it’s bigger than a cat, it doesn’t have the long tail
of a cat and it doesn’t miaow, so it’s definitely not a cat.
When we, as humans, first encounter something that we’ve never seen before, we try and work out what it is
based on several factors. We use our own inbuilt neural network to find points of reference, memories and
perhaps colours and shapes that we can refer to. So, if you see an unusual animal for the first time, for
example a Capybara, you might say, “It’s got
four legs and brown fur… Is it a cat?” But you can see it’s bigger than a cat, it doesn’t have the long tail
of a cat and it doesn’t miaow, so it’s definitely not a cat.
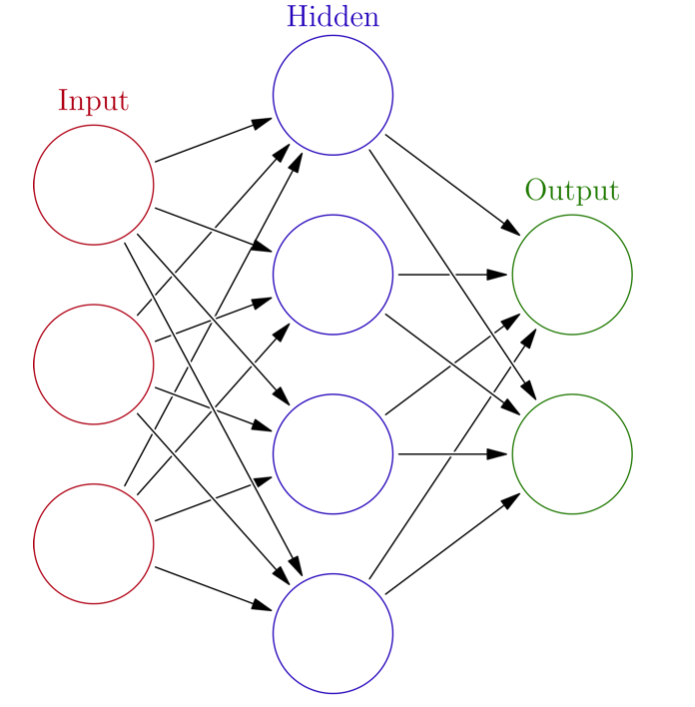
Deep learning needs to have these input layers created and inserted into the memory banks. If you’re creating a cat identification app, for example, you would insert your source image, or images and establish an algorithm that the software uses to identify whether it is presented with a cat later on. This would involve setting up sequential layers of data, such as identifying if it has fur, two ears, whiskers and so on, with the calculations needing to pass each layer to provide a successful identification of a cat.
This process is referred to as ‘Forward Propagation’, and every time it makes a mistake such as identifying a dog as a cat, it calculates the error and proceeds to do the inverse of Forward Propagation. It then works backwards through the layers until the first layer of the Deep learning architecture, which is called Back Propagation. This is the mechanism through which the networks adjusts and gradually makes fewer and fewer mistakes.
Most deep learning technology refers to architectures with as much as 60 layers. Of course, you can have fewer layers, or much more, but the more layers you have, the more details can be detected.
With your app referring to so many layers, hopefully the base output will understand what a cat is. It has whiskers, a tail and other feline features, therefore it’s a cat.
And hopefully, if your app is presented with the image of a dog, or a capybara, the app will say this is not a cat.
Common pitfalls
Like with all technologies, there are pitfalls with deep learning that usually require troubleshooting. Tiago explained how the most common problems with deep learning databases come down to overfitting or underfitting.
Tiago observes that the best way to spot issues with your software is that if you’re testing your design and it performs very well, it can be useful to split up your data sets into one for training and one for testing. The training one is what the algorithm will use to train and perfect the model, and the test set is used to check the resilience of the model against real world examples. The split for data can be anything from 0.1% for huge data sets, up to around 20%.
Overfitting
Overfitting is when you have trained an algorithm on a dataset that performs well on the training set, but that does not handle new input well. This is usually because the training data, or input, is too small, or even that there are too many layers. For example, if your cat identification app has so many layers to identify a cat, and perhaps a few exceptions to identify a dog, every exception could end up being a dog, even if it’s a sheep, a fish or anything else.
Some other suggestions for editing the performance include data augmentation, editing some of the images or reducing the complexity of the neural network. In some instances, such as an image recognition app, just cropping an input image can help to improve the data recognition and the final output.
Underfitting
Underfitting, on the other hand is when your model does not perform well, usually because the model is too simple. This is often as a result of insufficient data or a poorly mapped neural network. Fixing underfitting normally means adding more hidden layers for the program to refer to.
Popular tools for developing deep learning
There is plenty of choice for developers looking to create software with deep learning capabilities. The best tools are:
- Keras
- TensorFlow
- CNTK
- Theano
- PyTorch
Most of these are accessible via Github and are developed primarly by the large tech companies - Google, Microsoft and Facebook.
Tiago chose Keras to showcase his demo, which used Python as its code.


