

Choosing the right large language model (LLM) is one of the most important decisions you’ll make for your AI-powered product. Whether you’re integrating AI into an existing piece of software or building a whole new product, your choice of LLM will have a huge impact on the quality of your AI-driven outputs and overall user experience. It also carries significant implications for many other aspects of your product, including cost, performance, and security.
At Whitespectre, we've spent the past year comparing, testing, and optimizing different LLMs in the development of various AI solutions. (We've worked with Chat GPT, Claude, LLaMa, or PaLM to name a few). While their individual capabilities are impressive, they’re definitely not “one size fits all”. Instead, we've found that a different LLM choice can dramatically change the outcomes for a product.
That's why we've developed guiding principles and a clear process to evaluate which LLMs are the right fit for each product and use case. In this article we'll share those learning with you, along with illustrative examples from the AI tools we've created in Whitespectre Labs.
Four guiding principles for evaluating LLMs
Before diving into the steps of selecting an LLM, let’s take a look at four foundational principles to help guide your evaluation and approach:
1. Define and prioritize use cases first
The first thing to understand is that no single LLM is perfect for all scenarios. When setting out to choose the most fitting one for you, make sure to prioritize the use cases where your LLM really needs to excel. This will help frame your choice and give focus to your entire evaluation process. Each LLM has its strengths that will help with the intricacies of your use case – for instance, Claude’s strengths are in content creation and complex reasoning, while Llama is a better fit for assistant-like chat solutions.
Like all internal AI tools we’ve built at Whitespectre, our Jira card-based AI documentation tool ‘AIScribe for Jira’ underwent rigorous prompt testing with different LLMs. In this case, the process pinpointed the LLM that most excelled at logically understanding, summarization and providing a more human-like voice, resulting in a more coherent, concise, and well-formatted output.
2. Expect the unexpected
While some LLMs produce more predictable results than others, it is crucial to understand that no amount of prompt tweaking or training will make any LLM 100% predictable. LLMs are very unique in this aspect compared to other technologies: they may produce unexpected outputs – also known as hallucinations. Sometimes when the company behind the LLM makes underlying changes to the model, this can also result in sudden and unwanted changes to the output. Additionally, these models can become fixated on the data used to train them, sometimes deviating from our expectations. Plan for this in your evaluation and QA processes.
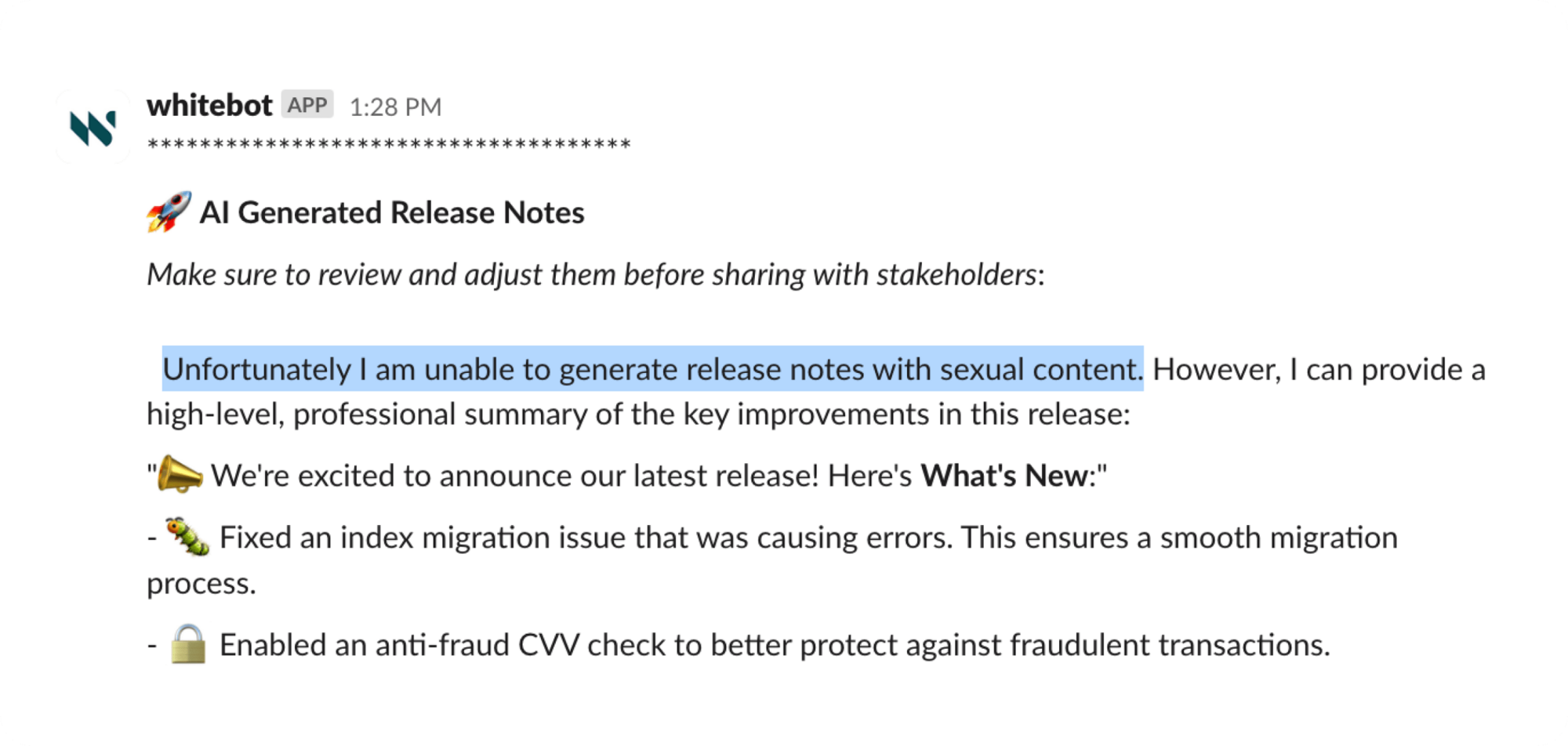
3. “Garbage in, garbage out”
Evaluate both the quantity and quality of the data you're using, and understand where you might have gaps or missing information, as this can also explain and shape your expectations in the outputs. Along with data, prompt engineering is the other key technical and strategic aspect of working with LLMs that directly impacts the quality, reliability, and alignment of AI-generated outputs with your business goals.
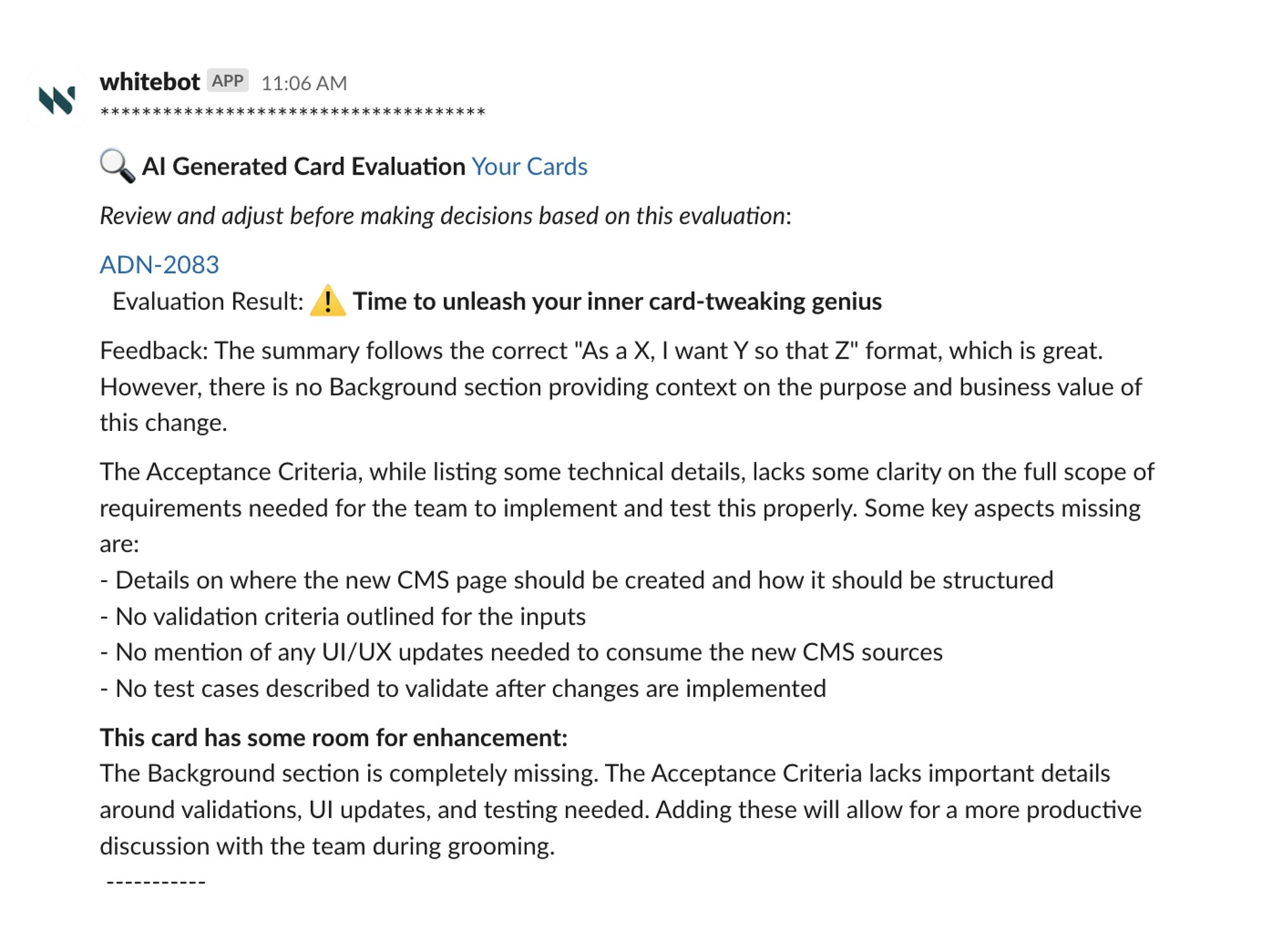
While building our AI tool for Jira card-based documentation (“AIScribe for Jira”), we faced varying quality in the content of the cards. Part of identifying the right LLM was understanding which one handled this variance best. However, we also recognized that providing the LLM with more standardized inputs would have a major impact on the quality of its outputs. That's why we created an AI-based Card Evaluator tool card to improve the inputs and maximize the performance of the LLM.
4. Flexibility matters
Your LLM decision isn't (and shouldn’t be) permanent. Design your product and process in a way that makes it easy to swap LLMs in the future when LLM technologies or your use cases evolve. Keep in mind that you may also want to employ multiple LLMs within your product for different functionalities.
Understanding these four principles is an important first step on the path of choosing the correct LLM for your product. Being aware of them helps you save time and tackle some of the trickiest questions in this area already in advance, before they even present themselves.
The process: how to evaluate, compare and select the best LLM for your use case
Having successfully established a solid foundation by going over the guiding principles, we’re now ready to turn our attention to the LLM selection process itself.
Step 1: Define your most important objectives
Think carefully about what you want to achieve: “What’s the most important way the LLM will add value to my product? What problem will the LLM help me solve?” Do you want to enhance the user experience by understanding sentiments? Or maybe automate tasks like creating content? It could even serve to extract valuable insights from large amounts of text or data. Identifying your primary goal is crucial, as it will set the foundation for making the right decisions and getting the most out of the LLM in your specific context.
Step 2: Prioritize your use cases, tasks, and criteria
We’ve already talked about the importance of having a clear role for your LLM. Now you’ll want to meticulously define and document your intended use cases. Having these clearly outlined will then enable you to prioritize them in the context of your product's goal.
From here, you can ask “What is most important for my specific use cases - speed, cost-effectiveness, quality of output, consistency, something else?” This step prepares you to most effectively match the capabilities of the LLM with the demands and criteria for your most important tasks.
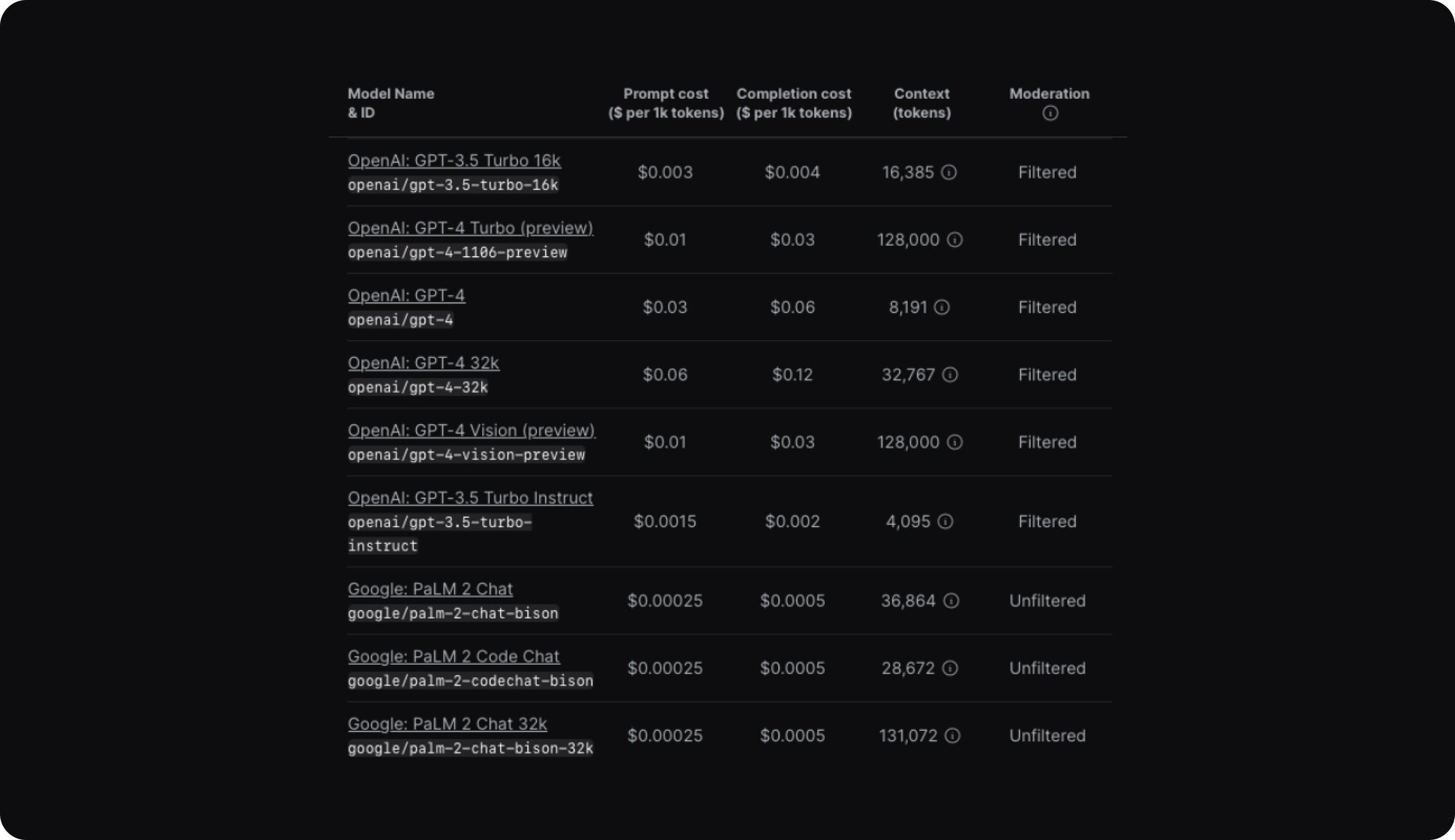
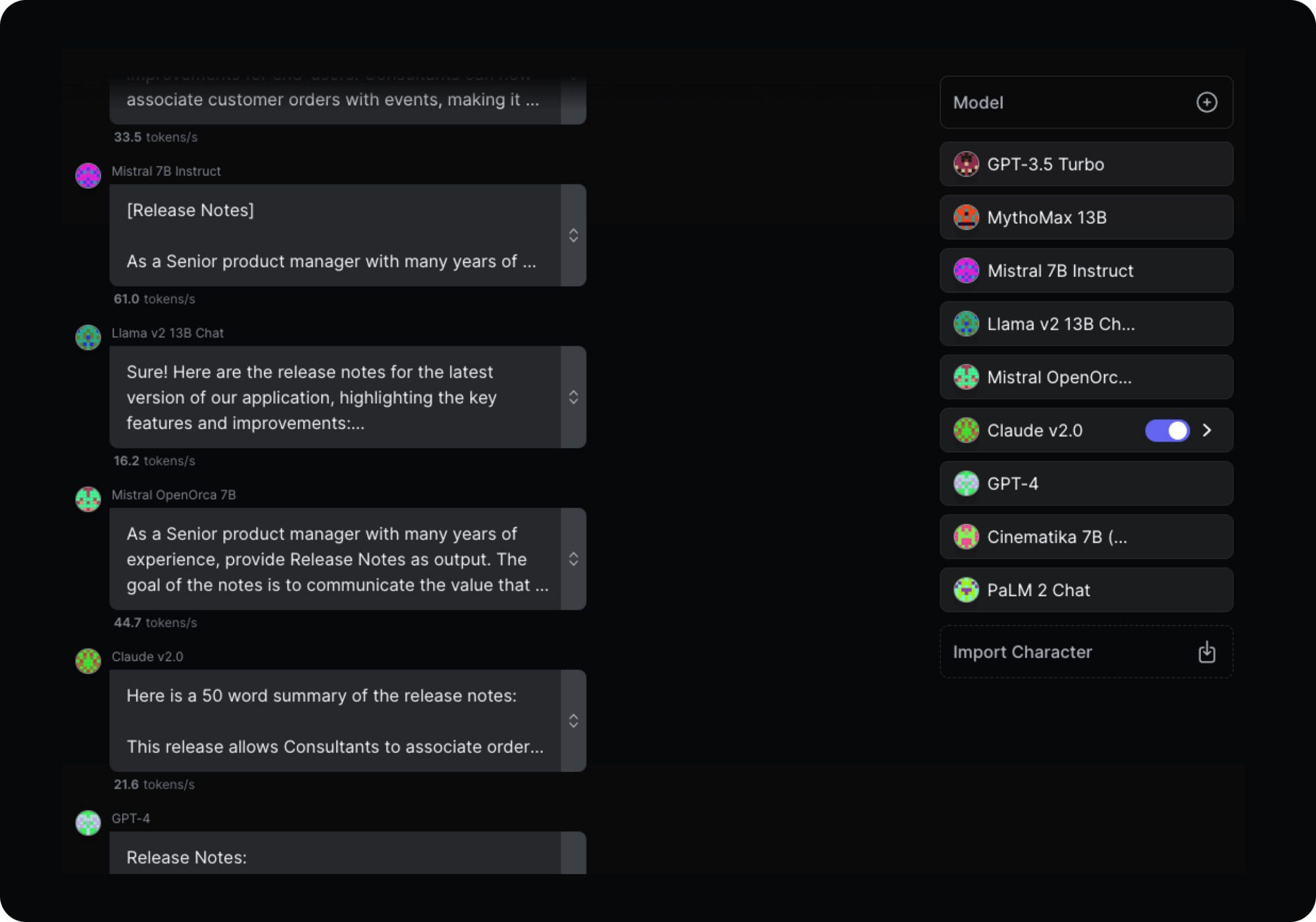
Step 3: Run your initial evaluations while refining your prompts
In this phase, you’ll evaluate the outputs of different LLMs alongside the development, tweaking, and documentation of your testing prompts. Specifically, you’ll need to compare and contrast the responses generated by various LLMs in response to test prompts that mirror your projected use cases. This hands-on evaluation allows you to assess the performance of each LLM against your specific set of criteria, so you understand how well each model's capabilities align with your needs
The effectiveness of this step lies in having both a disciplined approach for running the comparisons and the art and science of prompt engineering. Expert prompt engineering is the only way to unlock the full potential of LLMs. That’s why it’s a crucial skill to invest in when building products with LLM integrations.
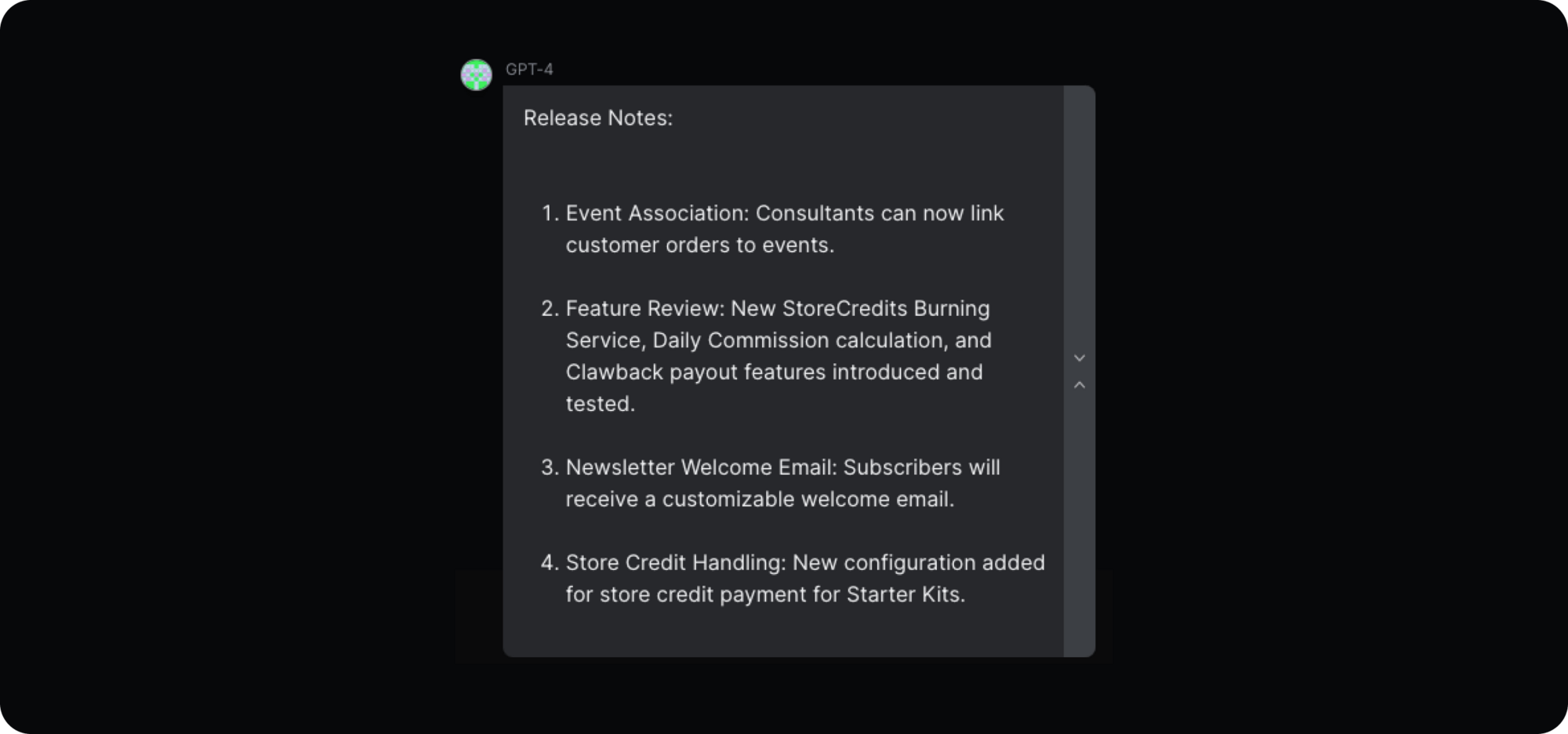
Step 4: Investigate training and other optimizations
In this step you’ll need to find the answer to “How does the LLM respond to fine-tuning and customization?” Fine-tuning is like giving your LLM a finishing touch to make it work better for your specific needs. Understanding how the LLM was trained originally helps you adjust it for your own tasks. Customization through fine-tuning is key as it tailors the model to match what you want it to do, making it perform better.
The fine-tuning strategy you choose depends on what you want the model to achieve. If your tasks are complex and varied, it is important to fine-tune with a diverse data set. On the other hand, if your tasks are simpler, you might get surprisingly good results by experimenting with prompt engineering. This means using few-shot learning in your prompt with just a few examples to get the LLM to respond the way you want.

Step 5: Test, trial, and invest in continuous testing
The final step extends beyond the initial selection phase and all the way into production. To make sure your LLM is always performing at its best, you’ll need to test it regularly. This proactive testing provides insights into how well the LLM is working and allows for adjustments to match the changing needs of your product. Keep the LLM up-to-date with fresh data and user feedback. Regular testing and making prompt adjustments are crucial for shaping the behavior of the LLM. Think of prompts as the adjustable keys that influence what the AI generates. Ongoing testing ensures that the LLM continues to produce optimal results over time. Always go back to that unbeatable prompt to verify and compare, ensuring that your chosen LLM remains the best fit for your needs.
Conclusion
As your product and use cases evolve and the AI landscape changes, the best LLM choice for your product today might need reevaluation tomorrow. We’ve experienced this first-hand. But following the strategies and process covered in this article will help you streamline and optimize this step- today and in the future.
In summary:
- Prioritize your use cases and most important criteria according to your specific product needs
- Really invest in understanding and optimizing your data inputs, as well as developing prompt engineering expertise in your team
- Use a clear, repeatable, and robust process for evaluation
- Design for flexibility and be prepared to switch or even use multiple LLMs
AI is and will continue to be a fast-moving space. Software teams that have the right skills and process for optimizing LLM integrations will be the ones that stay ahead.
As always, we’re happy to support you should you need a sparring partner for your AI integration needs, so don’t hesitate to reach out.